
Our product is only as valuable as it is usable, and for a complex product like Appian, we know that documentation is a key element to supporting developers and helping them succeed.
Early in 2020, Appian acquired the Robotic Process Automation (RPA) company Novayre to integrate its RPA product into our platform. RPA brings a lot of exciting opportunities for developing applications and processes, but how would we help customers realize that potential as quickly as possible?
On the Information Development team, we create and advocate for documentation as a piece of our product each release. We knew we’d have to get things in order docs-wise when Appian RPA debuted in 2020. To support that mission, I was put in charge of the project to migrate the existing RPA content from Novayre’s environment to docs.appian.com. I also took the opportunity to work alongside developers and product owners as they morphed Novayre’s Jidoka product into Appian RPA.
In this post, I’ll review the challenge at hand, the approach I took for migrating documentation, and some lessons I learned in the process.
Evaluate what you’ve got.
Technical writers are taught early on to put themselves in the shoes of their audience and write accordingly. So when this project landed in my lap, my first instinct was to get familiar with the subject and the feature set. At this point, I was focused on learning about general RPA concepts as well as the ins and outs of Jidoka, Appian RPA’s predecessor. Because I was migrating documentation from our newly acquired company’s repository, I needed to understand the context and relative importance of each piece of documentation.
One way to organize content is based on how readers approach the product, so it makes sense to understand that from the start. Getting familiar with the existing content also gave me the opportunity to identify redundancies or gaps to keep in mind. As tempting as it was to just jump in and mix things up, I took the time to read the documentation (technical writers sometimes struggle to do this too!) and understand what I was working with. I also wanted to understand the product’s capabilities, so having points of contact on the development team was really helpful.
When I had the context to begin thinking critically about how this would look on our docs, I had to set up my approach so it fit with our team’s way of doing things. Appian’s InfoDev team uses a “docs-as-code” approach to edit and manage documentation, so I set up a branch in my local docs repository to help with version control and to push my changes to our remote branch in GitHub.
Then it was time to think about specifics. How has the existing Jidoka documentation been written and maintained, and how can we migrate it to our environment? Appian docs live in a static site created with Jekyll and written in Markdown, so my end goal was clear. However, the source content lived in Atlassian’s Confluence tool, where the export options were limited to XML, HTML, and PDF. Manually converting the content was out of the question, so I did a bit of research and found a tool called Pandoc to make the work much easier. It took some practice to determine the tasks best suited for this tool — Pandoc handled text conversion consistently well, but images and links didn’t convert as easily and used a different Markdown format than docs.appian.com. These issues weren’t a dealbreaker for using the tool, but just something to keep in mind during the cleanup phase. After a small pilot, I was able to convert ~300 files from HTML to Markdown in seconds.
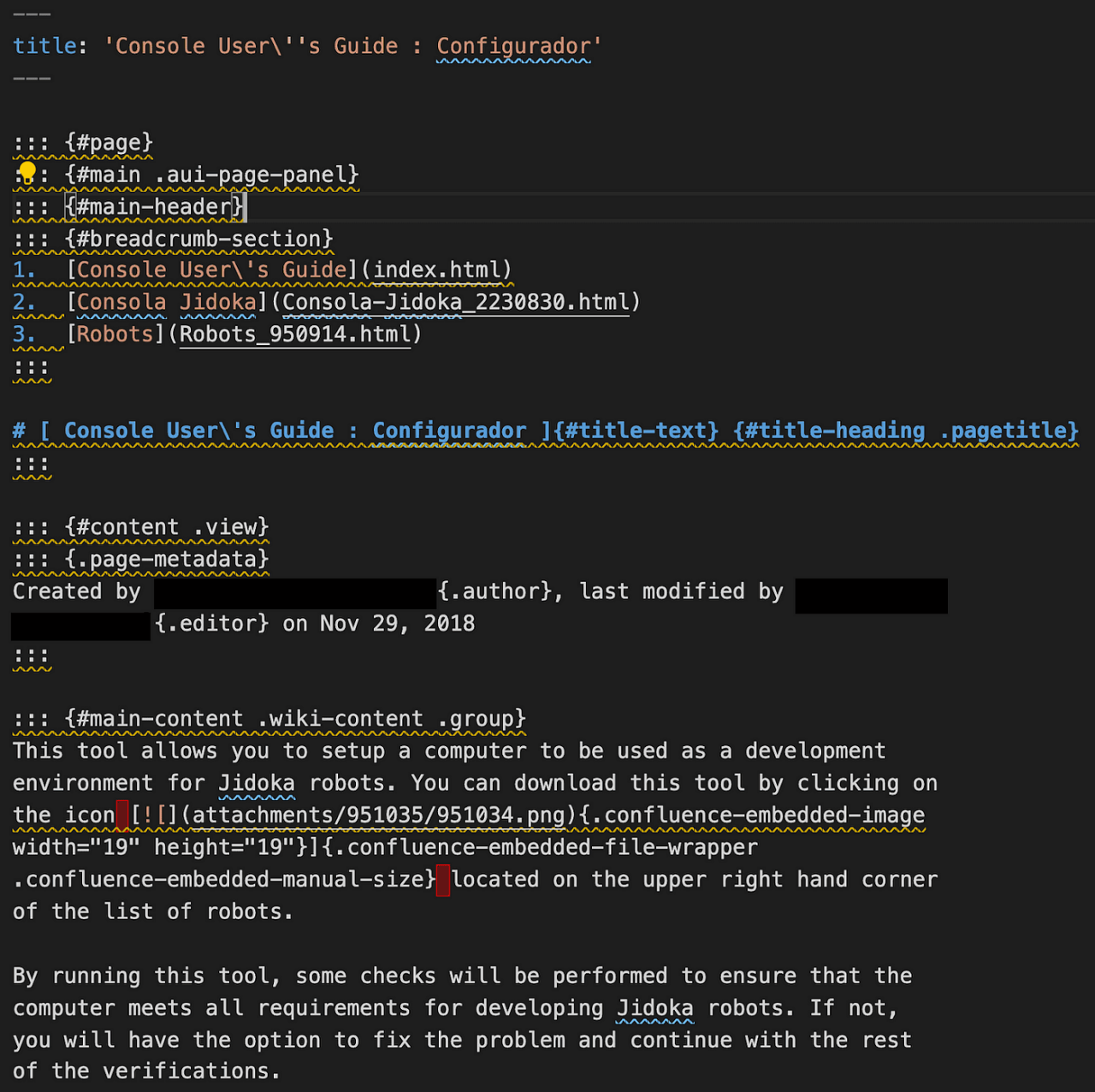 An example of the exported and converted content. It still needs some work to meet Appian’s docs standards.
An example of the exported and converted content. It still needs some work to meet Appian’s docs standards.
Now that the basics were taken care of, it was time to move to the next phase of the project: beautification.
Determine what you need.
First things first — before you make things look great, figure out what content you need. In this case, that means working with the development team and product owners to determine how Appian RPA is changing during the Novayre acquisition. Our docs need to match what users see so they can achieve their goals more quickly and without confusion — after all, if a feature or option is being removed, the content should, too.
It’s tough to manage 300 pages and make sure the essential content makes it into a new structure. So to help keep things straight, I made a mindmap (using mindmeister.com) to help connect the dots between existing content and the ideal state. This visual organizer made sure things didn’t slip through the cracks.
 Sample of the mindmap I used to organize content during the migration
Sample of the mindmap I used to organize content during the migration
Do the thing.
After determining what to do, I wanted to vet these assumptions with my team’s product owners and other content developers on my team. Docs and product work hand-in-hand, and it’s easy for writers to get too close to the project. I wanted to ensure my approach would make sense for new developers as well as those who have worked with RPA in the past. The product owners also helped me assess what type of content Appian designers would need to get started integrating RPA with their existing applications.
When the outline was approved, I had the green light to proceed. The mapping I created during the planning phase had an unintended benefit of dividing up the work into chunks, so I could focus on editing groups of content before moving on to other concepts. When I thought I was finished, I could refer back to the original outline to visually see if everything was accounted for in my new organization. With each major change, I committed my changes in my local branch so I could easily roll back if anything went wrong.
As mentioned earlier, Appian’s doc site is built using Jekyll and Markdown. We use front matter properties on each file to structure the content on the site. Pandoc can create some of these properties, but others would need to be determined after the content was reorganized. For example, I knew that each page would use the `layout: basic` property, but I didn’t know what to use for `weight` yet because the order of pages in the content browser wasn’t determined. To create new front matter, I used regular expressions and a simple Python script to add or change the information by content group.
Regular expressions were also immensely helpful for cleaning up the converted files. I was able to delete all stray Confluence markup tags, change incorrect formatting, and systematically make other updates using regular expressions, a little Python, and a browser-based tester to verify my regex (I’m fond of regex101.com). I wrote and ran many regex find-and-replace scripts to find patterns of content I wanted to eliminate or change. Once again, what would take hours to complete manually instead took minutes.
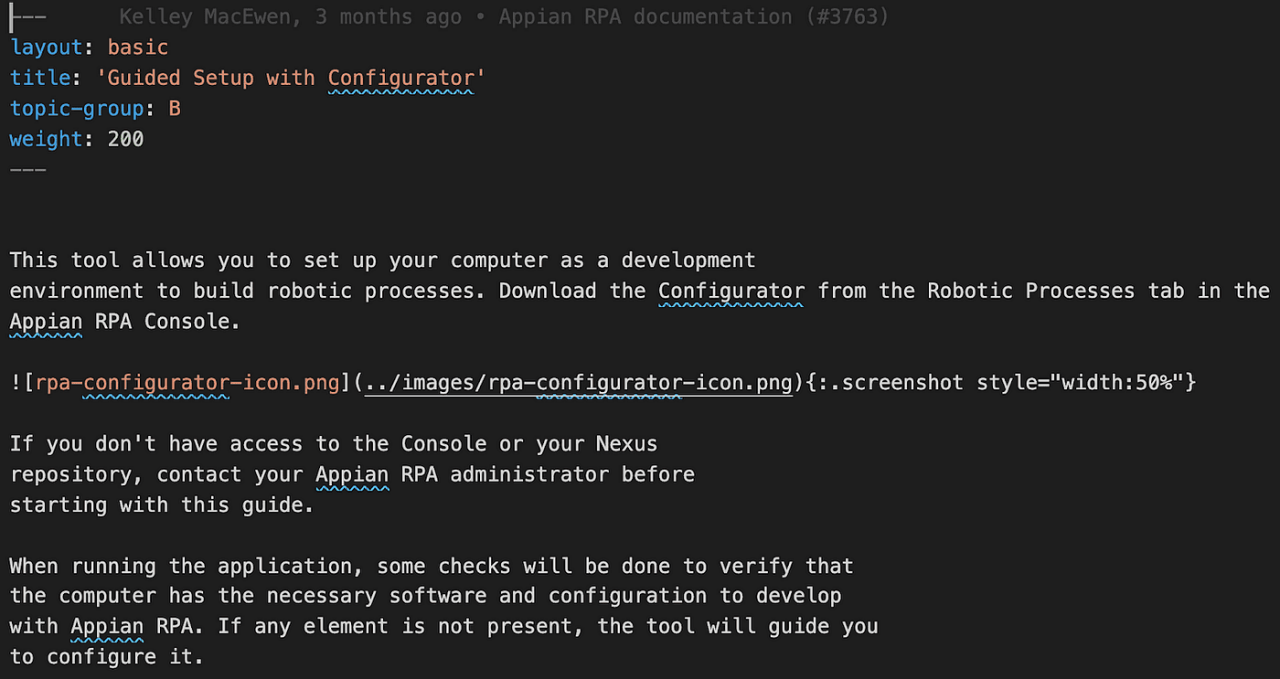 An example Markdown file cleaned using regular expressions.
An example Markdown file cleaned using regular expressions.
After that, it was time to go over each file with a fine-tooth comb. Checking links, replacing images, revising for readability — all routine in the documentation lifecycle. I couldn’t really automate these tasks, so instead I had to bring some human touch to content creation: considering our style guide and general copywriting best practices to help the content really shine and fit within our existing docs.
How’d it go?
The docs were released alongside Appian 20.1 and have been prominently featured in each subsequent release. Feedback from our customers and partners have undoubtedly helped improve the usability of these docs, and we’re looking forward to more of that. For example, discussions on Appian Community have helped us understand where docs might be unclear or incomplete.
Behind the scenes, I learned a lot about migration projects. In eight weeks, I migrated 300 pages of content from Confluence to Markdown, including strategic reorganization, and drafted additional content for Appian users to get up to speed. It was one of our team’s first opportunities to work embedded on the scrum team using the same process our development teams do, and it helped me stay on top of changing features and priorities much more efficiently. Each team member brought great ideas and feedback to the table to make the docs better.
The tools I discovered along the way were immensely helpful in saving time and frustration, as well as reducing errors. Speaking of, I didn’t have to reset my changes often, but using git as my version control system was also essential to keeping my sanity at times. I had a full trail of changes I had made and could easily retrace my steps when necessary.
What would I do differently? At the time, I was still getting used to the “docs-as-code” and agile documentation practice, so I could have asked for feedback sooner in my process. To help shield my team from poorly formatted or incomplete docs, I didn’t share a preview of the docs as early as I should have, which condensed their review period. Having less time to review and incorporate feedback puts stress on everyone, so I’ll avoid that in the future. I believe editing is never finished, so I’ll continue to look for opportunities to improve with each release (including letting go of perfectionism).
This was one of my first opportunities to lead a documentation migration project and, based on the preceding novel, it was quite an experience. I hope you’re able to find something useful from this particular case. Or, if you’re an Appian RPA user and have thoughts on how to improve the docs, please share using the Feedback widget on any Appian RPA page!
By the way, I summarized this project in an Appian Talk last summer to share my experience with the entire Engineering department. Appian Talks are just one way we learn from each other at Appian. If you’re looking for a role where you can experiment with new technologies and share that knowledge, apply today!